

智慧型機器手臂–第二部分:程式設計

目錄
- 簡介
- 第1步:製作App
- 第2步:如何製作Demo App
- 第3步:App屬性以及第4步:人臉辨識
- 第5步:天氣API以及第6步:語音合成
第3步:App屬性
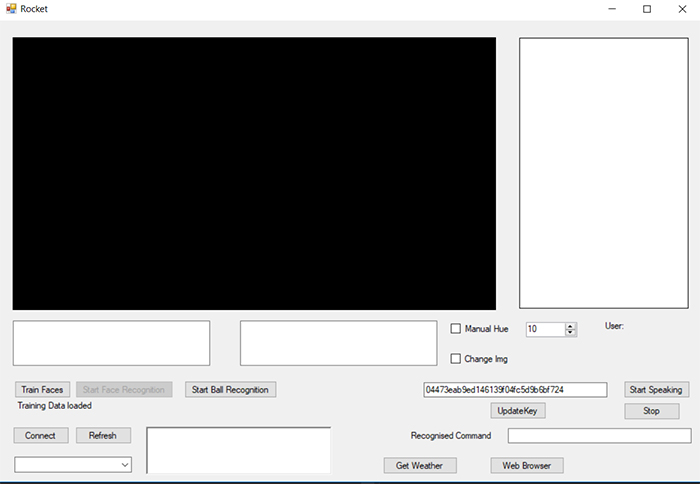
憑藉.NET、OpenCV和Microsoft API的功能,我們能夠製作出完整的應用程式。對於該應用程式,我們需要按鈕、序列埠和文字方塊。
黑色視窗會顯示來自相機的圖像,視窗中還會添加一個鏡頭框,框內顯示人物名稱。
左側的白色視窗可以添加TTS API(文本轉語音)的文本,提供回饋以檢查工作,並檢查說出的文字是否與顯示的字詞相符。
圖8 機器人手臂應用程式
第4步:人臉辨識
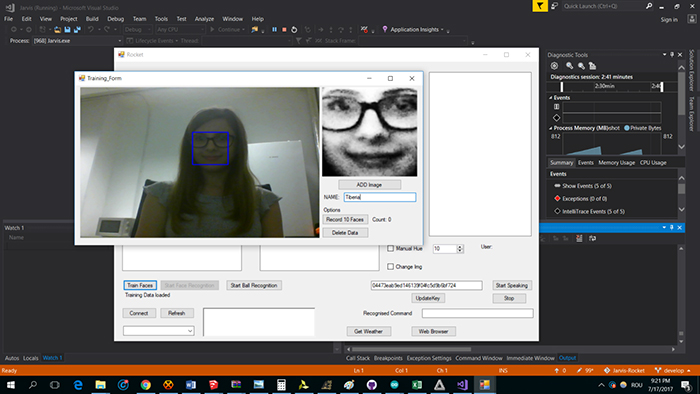
為了獲得更好的程式結果,您需要在訓練模式下添加多個臉部記錄。訓練是指通過拍攝多個臉部位置以獲得最佳辨識結果(不同拍攝角度、光線條件等)。您需要按下Record 10 Faces按鈕,通過應用程式記錄臉部畫面。
在代碼中,實現這個功能的語句為Face = Parent.faceClassifier;這通過EmguCV平台完成。人臉偵測通過基於主成分分析(PCA)的複雜演算法實現,系統會將偵測到的臉部與訓練後儲存的圖像進行多次比對。
圖9 人臉檢測
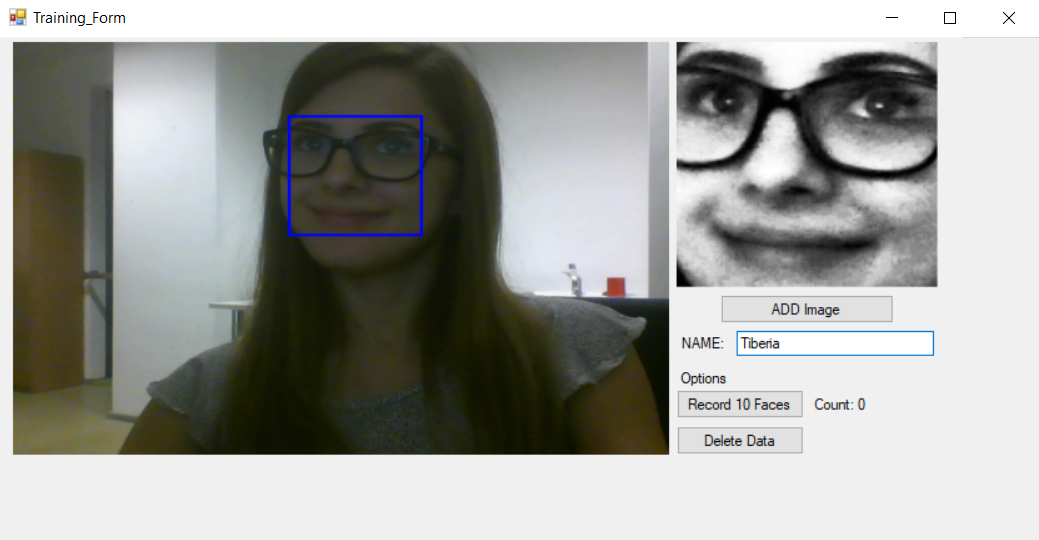
藍色矩形中的圖像是需要儲存的圖像,因為它包含臉部的獨特特徵。
我們需要在不同的位置和不同的光線下獲取更多的臉部特徵:
圖10 添加更多人臉進行訓練
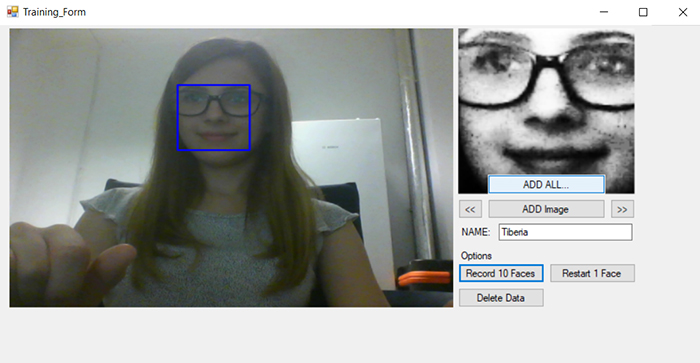
經過一系列臉部偵測圖像拍攝,如果您認為之前記錄的臉部圖像不利於演算法計算,那麼可以點擊Restart 1 Face按鈕刪除已經保存的檔案,系統將不再偵測該臉部資訊。
如果要記錄多人數讓機器手臂可以進行區分,那麼可以使用Delete Data按鈕刪除照片。
圖11 重啟訓練模式
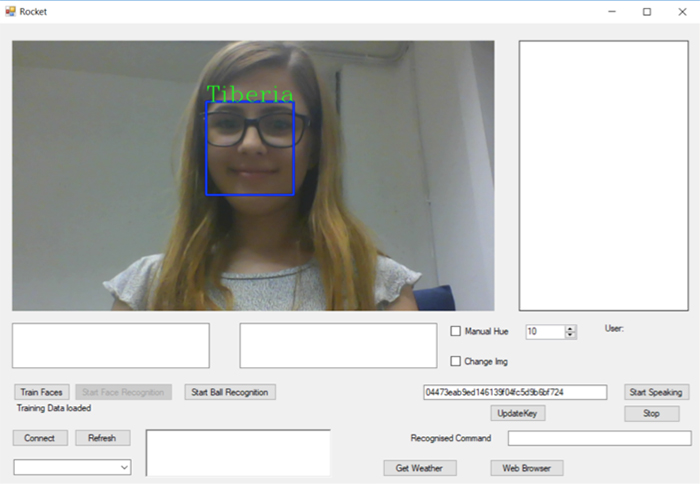
錄製更多圖像後,該演算法應該能夠偵測人臉,並在藍框上方顯示名稱。機器人可以精確偵測像眼鏡這樣的特徵,因為這些特徵具有區別性。
圖12 訓練之後的結果
Tiberia Todeila
Tiberia目前是羅馬尼亞布加勒斯特理工大學電氣工程學院的大四學生。她非常熱衷於設計和開發讓日常生活更輕鬆的智慧居家設備。